Nobody builds their own payments infrastructure anymore. Neither does one buy a chartered plane when in need of a business-class ticket. Soon, enterprises will follow the suite for Voice AI too instead of their engineering teams being deployed to build voice AI stack in-house.
When an enterprise wants to fly its executives business class, it buys a plane ticket. It does not purchase aircraft, hire pilots, negotiate airport slots, or set up an MRO facility. The value of the trip is in getting from A to B, not in the operating machinery underneath.
The same has been the case with payment infrastructure. For instance, in 2009, if you wanted to accept credit cards on your website, you hired a developer to integrate with a bank, obtained a merchant account, built tokenisation logic, and handled PCI [Payment Card Industry] compliance yourself. By the time it was up and running, your team probably spent six months doing it. Then came Stripe, and that entire category of engineering effort quietly became optional. The companies that kept building their own payments stack did not get a competitive advantage, but a giant maintenance burden, laden with new compliance every now and then.
Voice AI is perhaps going through similar waters. Across BFSI, e-commerce, and collections, we keep seeing the same story: a product team estimates the in-house capabilities to build a Voice AI wing in an effort to reduce costs, an engineering team gets tasked with a routine PRD, and 6-12 months later, the company has a half-working voice chatbot, bombarded with plenty of vendor contracts, and a full-fledged team that now owns a problem it wasn’t initially recruited for.
Table of contents:
- What teams invest in when they build the Voice AI stack in-house
- The model churn and new launch problem that doesn’t get talked about while engineering teams build voice AI stack
- Domains where this plays out: BFSI, Quick and E-commerce, Healthcare and more integrating Voice AI stack
- What you are actually paying for when you build in-house Voice AI stack capabilities
The correct question for enterprises is not whether your engineering team is capable of building a voice AI calling agent. They most definitely can, given enough time, budget and dedication. Perhaps, the enterprises should rather consider what building one actually costs the business, who ends up owning it, and whether that trade is worth making when the underlying technology is moving this fast with new updates dropping every other week.
What teams invest in when they build the Voice AI stack in-house
Let’s inspect what goes into building a voice AI stack from those who have done it from scratch while it was still emerging. A production voice agent is not a single API call alone. The basic structure itself will need to stitch together a telephony layer (Twilio, Exotel, Vobiz or equivalent), a speech-to-text [STT] model [Deepgram or Sarvam for Indic languages], a large language model [LLM, say ChatGPT 5.1, or Gemini], a text-to-speech [TTS] engine [ElevenLabs, Cartesia, or similar], and an orchestration layer [Bolna or similar] that coordinates all of them together to make it functional enough to trigger a call.
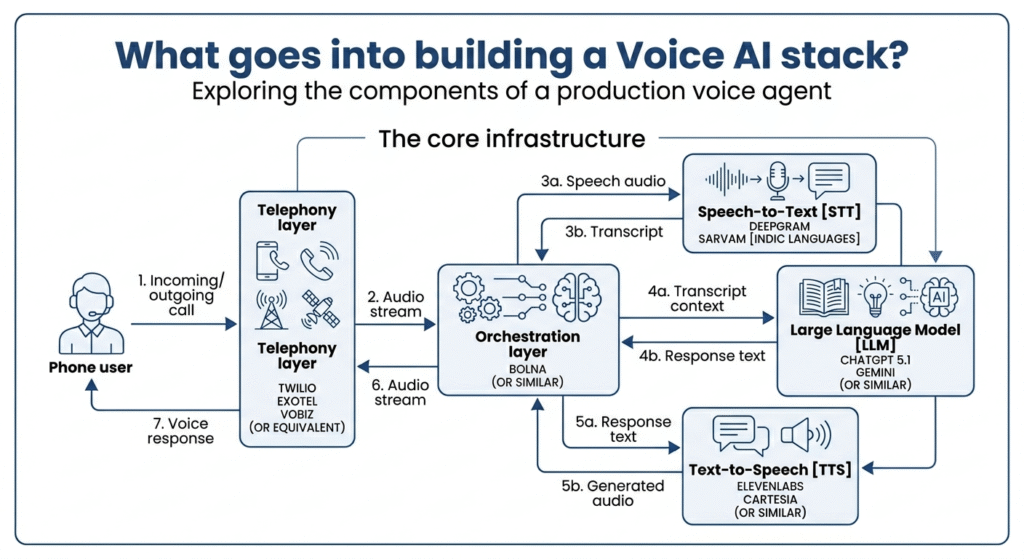
When deployed well, the calls must replicate human-alikeness. But here is the trickier part. Human conversations tolerate about 1 to 1.5 seconds of silence before the interaction starts to feel broken or lagged. Getting end-to-end latency under 500ms in production, across variable network conditions, with interruption handling and barge-in detection, is genuinely complex engineering developed with an immense amount of edge cases deliberated over and over again.
Vibe-coders might consider it a weekend project, but it takes months of work, understanding refined with deeper research and workflows involving various use-cases from large-scale enterprises to make it work without it getting torn apart in production.
The model churn and new launch problem that doesn’t get talked about while engineering teams build voice AI stack
Here is the part that makes the build argument worse over time as the technology gets an update every single week. In the eighteen months between January 2024 and February 2026, more than fifteen to twenty distinct frontier voice models were shipped into production. ElevenLabs released Flash v2.5, bringing latency down to roughly 75ms, Cartesia shipped Sonic which was purpose-built for real-time, Deepgram launched Nova-3 with measurably improved word error rates on accented speech. Sarvam released Bulbul V3 with better Indic language support, and OpenAI launched a real-time audio API.
Each of these releases changes the primary configuration of a voice agent stack. If you have built in-house and fine-tuned your prompts and fallback logic around a specific model, a new release is not an upgrade but instead, a migration with regression testing, re-tuning and re-evaluation of every edge case your team has spent months learning, depending on iterations.
An orchestration platform handles this by design. Bolna amasses multiple model providers simultaneously on its platform, benchmarks and deploys new releases against production call data, and routes the calls to better models as they become available at scale to deploy it for multiple enterprises across domains. The enterprises take note of these rapidly evolving improvements but fail to see the iterative work that goes behind the flawless orchestration.
Domains where this plays out: BFSI, Quick and E-commerce, Healthcare and more integrating Voice AI stack
Think of collections in BFSI. For instance, an NBFC with a borrower base spread across Maharashtra, Tamil Nadu, and UP is running hundreds of thousands of outbound calls every single month. The borrowers speak various Indian languages i.e. Hindi, Marathi, Tamil, and Telugu, sometimes even switching in between these languages mid-sentence. A polyglot human agent can handle this naturally. On the other hand, a voice AI agent could handle it only if the speech recognition model is genuinely good at language switching built for the complexity of Indian languages; which most general-purpose models, built primarily for English, are generally not.
And if not for the language problem, BFSI collections calls are heavily regulated and required to be compliant with regulators. TRAI’s Telecom Commercial Communications Customer Preference Regulations, 2018 [TCCCPR] framework and RBI’s fair practices code both impose constraints on when you can call, what disclosures you must make, and how escalations to humans must be handled.
An in-house team building for the first time will encounter all of this in production or worse, during deployment post getting banned; that is, much after initial conceptualisation, and not in the planning stage. For somebody solving this for a whole domain of enterprises, the compliance logic is not additive or optional but structural.
Let’s look at another rapidly scaling industry in gig-economy. A voice AI deployment in Q-commerce recruitment sounds simpler but has its own version of this problem. A warehouse running Blinkit or Zepto dark store operations needs to screen hundreds of potential delivery executive candidates per day during peak cycles or festivities. The job demands change by the week depending upon the sales projections and category additions. The required languages change by pincodes and the volume of orders spikes unpredictably. A human recruiter team cannot cater to this problem at scale in any cost-effective way. A voice AI agent, however, can but only if it can be reconfigured quickly as requirements shift. That again, is an orchestration problem, and not a model problem.
For e-commerce deployments, cart abandonment recovery is another case where timing becomes everything. The stats consistently show that the first hour after a cart is abandoned is dramatically more effective for recovery than any follow-up window after that. So getting a voice agent live, integrated with your cart data, and calling customers within minutes of abandonment requires a stack that is already built and tested by the e-commerce players.
What you are actually paying for when you build in-house Voice AI stack capabilities
Two decades ago, Stripe’s insight was not just that configuring payments was hard. It essentially hypothesised that payments were hard in ways that were identical across companies, be it small or big. Observantly, every startup was solving the same PCI [Payment Card Industry] compliance problem, the same tokenisation problem, the same webhook reliability problem. Stripe became the payment infra pioneer by amortising that cost across thousands of customers and charged each of them a fraction of what it would have cost to build alone.
The same logic applies here as the Voice AI domain scales up. The latency engineering problem, the multilingual model problem, and the compliance or regulatory problem: these are currently [and would remain] identical across every enterprise doing voice AI in India. Bolna has solved them once from scratch, in production, and at scale. Spreading that cost across customers makes the math obvious.So what enterprises should essentially be building is the layer above this is obviously the call strategy, the escalation design, the integration with their CRM, and the measurement of what is working. Those are the decisions that require domain expertise and are the ways forward to win. Safe to say, focussing on these decisions that produce competitive advantage will actually pay off.
The orchestration layer is better left to the specialists, the differentiation lies in the strategy. The wisdom lies in acting accordingly.